
RSA encryption allows for anyone to send me messages that only I can decode. To set this up, I select two large random primes 

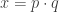


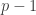
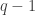
The beauty of RSA encryption is that using only the information I publicly released, anyone can encode a message they want to send me. But without knowing the values of
On the surface, RSA encryption seems uncrackable. And it might be too, except for one small problem. Almost everyone uses the same random-prime-number generators.
A few years ago, this gave researchers an idea. Suppose Bob and Alice both post public keys online. But since they both used the same program to generate random prime numbers, there’s a higher-than-random chance that their public keys share a prime factor. Factoring Bob’s or Alice’s public keys individually would be nearly impossible. But finding any common factors between them is much easier. In fact, the time needed to compute the largest common divisor between two numbers is close to proportional to the number of digits in the two numbers. Once I identify the common prime factor between Bob’s and Alice’s keys, I can factor it out to obtain the prime factorization of both keys. In turn, I can decode any messages sent to either Bob or Alice.
Armed with this idea, the researchers scanned the web and collected 6.2 million actual public keys. They then computed the largest common divisor between pairs of keys, cracking a key whenever it shared a prime factor with any other key. All in all, they were able to break 12,934 keys. In other words, if used carelessly, RSA encryption provides less than 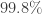
At first glance this seems like the whole story. Reading through their paper more closely, however, reveals something strange. According to the authors, they were able to run the entire computation in a matter of hours on a single core. But a back-of-the-envelope calculation suggests that it should take years to compute GCD’s between 36 trillion pairs of keys, not hours.
So how did they do it? The authors hint in a footnote that at the heart of their computation is an asymptotically fast algorithm, allowing them to bring the running time of the computation down to nearly linear; but the actual description of the algorithm is kept a secret from the reader, perhaps to guard against malicious use. Within just months of the paper’s publication, though, follow-up papers had already discussed various approaches in detail, both presenting fast algorithms (see this paper and this paper), and even showing how to use GPUs to make the brute-force approach viable (see this paper).
There’s probably a lesson here about not bragging about things if you want them to stay secret. But for this post I’m not interested in lessons. I’m interested in algorithms. And this one turns out to be both relatively simple and quite fun.
Algorithm Prerequisites: Our algorithm will deal with integers having an asymptotically large number of digits. Consequently, we cannot treat addition and multiplication as constant-time operations.
For 

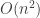
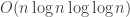
Computing the GCD naively using the Euclidean algorithm would take 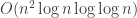
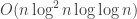
Fortunately, all of these algorithms are already implemented for us in GMP, the C++ big-integer library. For the rest of the post we will use Big-O-Tilde notation, a variant of Big-O notation that ignores logarithmic factors. For example, while GCD-computation takes time 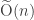
Transforming the Problem: Denote the set of public RSA keys by 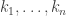
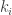

The Algorithm: The algorithm has a slightly unusual recursive structure in that the recursion occurs in the middle of the algorithm rather than at the end.
At the beginning of the algorithm, all we have is the keys,
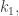
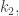
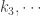
The first step of the algorithm is to pair off the keys and compute their products,

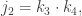
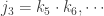
Next we recurse on the sequence of numbers 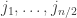
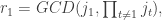

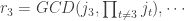
Our goal is to compute 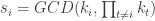

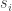
and that when
To see why this is the case, one can verify that the term on the right side of the GCD is guaranteed to be a multiple of 

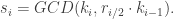
Computing each of the 
Bounding the Running Time: Let 

Therefore each of the 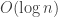

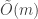
If we unwrap the running time into standard Big-O notation, we get
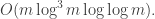
Is it practical? At first glance, the triple-logarithmic factor might seem like a deal breaker for this algorithm. It turns out the actual performance is pretty reasonable. This paper found that the algorithm takes time roughly 7.65 seconds per thousand keys, meaning it would take a little more than 13 hours to run on 6.2 million keys.
One of the log factors can be removed using a slightly more clever variant of the algorithm, which avoids GCD computations at all but the first level of recursion (See this paper). The improved algorithm takes about 4.5 seconds per thousand keys, resulting in a total running time of about 7.5 hours to handle 6.2 million keys.
So there we go. A computation that should have taken years is reduced to a matter of hours. And all it took was a bit of clever recursion.

Very interesting article. Thank you
LikeLike
Loved the article and now I want to try by myself. Thinking on how to collect a few million of certs, group them by used random generator and then try to crack them like this.
LikeLike
This is really well written, covering almost all prerequisite information for the topic. And the math is also well explained. Kudos!
LikeLike
But my question is how to PREVENT this from happening? How does one avoid having a a shared prime factor? Or can you?
LikeLike
Fully determining what must happen would likely take tracking down which keys fail, and what exactly made them share a prime factor. But I think a really solid guess is “Use a proper, well-seeded RNG”. Those little “shake your mouse” or “type some stuff’ or other “give me some physical events to ensure sufficient entropy”, do them. If you’re unsure where your random is coming from, look into it (hugely system dependent). Because, for sure, one way this would happen would be to run the same RNG (not much you can do there – like most crypto they’re generally well written and tested enough that any individual bright ideas do more damage at scale) and not have sufficient entropy to make them diverge evenly of the space. And it’s not particularly far fetched to think that one in five hundred-ish either used a generator that didn’t freeze up and be all “Whoa, human! This computer was just rebooted! /dev/urandom has a mere 64 bits of true entropy!” or used some other entropy creator that full-on says it’s not *sure* there’s enough, and just said “Whatever – what’s going to happen, you use a mere 32 bits of randomness instead of 128? In what possible way could someone leverage that into an attack?!”. Well.. this whole episode kind of fleshed that out – what was a theoretical flaw (very clearly a flaw, but none the less) is now a practical exploit, albeit one that doesn’t shred your encryption like tissue, but it does inject a 0.3%ish failure rate which is bad if you’re expecting five nines.
LikeLike
From memory, the original paper suggested these common factors came from embedded devices with almost no sources of available entropy, rolling an ssh key on first boot. Perhaps made by the same manufacturer.
LikeLike
yoink
LikeLike
Your runtime analysis seems off – in particular, it depends only on m, the length of the inputs, and not at all on n, the number of inputs. Also, in every step of the recursion, doesn’t the length of the inputs grow?
LikeLike
The analysis solves for the running time of the algorithm in terms of the sum of the lengths of the inputs. (Importantly, the sum of the lengths of the inputs either stays the same or shrinks between levels of recursion.)
LikeLike
if someone wants to see a simple implementation, I implemented it in python
https://github.com/DanielMagen/simple-multiple-RSA-break
LikeLike